GitHub人工智能AI开源项目
精品收藏:GitHub人工智能AI开源项目
pan_jinquan 2018-07-26 18:33:06 26205 收藏 317
分类专栏: 机器学习 学习笔记 深度学习 文章标签: GitHub AI开源项目 人工智能 姿态识别
版权
精品收藏:GitHub人工智能AI开源项目
绝对精品!!!花了点时间,鄙人把这几年收藏的开源精品项目,整理一下,方面以后查找。其中涵盖了姿态检测,图像分割,图像分类,美学评价、人脸识别、多尺度训练,移动端的AI 计算引擎,卫星图像,NLP,Python包,文字检测,NCRF,DALI 等开源项目。
更多开源项目,持续更细中……
目录
目录
精品收藏:GitHub人工智能AI开源项目
常见的的数据集
Model Zoo-机器学习预训练模型下载地址
DensePose-实时人体姿态估计
AlphaPose-姿态识别
MobilePose-支持移动设备、单人姿态估计框架
NeuralEnhance: 提高图像分辨率的深度学习模型
FaceNet-人脸识别算法
Age and Gender Estimation-年龄和性别评估模型
CornerNet-Lite目标检测
OD Annotation-目标检测数据集标注工具
Semantic Segmentation PyTorch-语义分割工具包
Photo Aesthetics Ranking Network -图像美学排名网络
Non-local Neural Networks for Video Classification-视频分类开源代码和模型
colornet-将灰度图转为彩色图
Visual Search Server-可视化搜索服务器
Darts-可微分的卷积循环网络结构
SNIPER-高效的多尺度训练方法
Mace-用于移动端的、异构计算平台的深度学习推理框架
Robosat-端到端的特征提取方法
DecaNLP-自然语言界的“十项全能”挑战
Magnitude-快速高效的通用向量嵌入式实用程序包
Porcupine-自助式的、高精度、轻量级文字检测引擎
NCRF-神经条件随机场结构,能够将检测到的癌症转移到WSI 中
DALI-数据加载库
常见的的数据集
搜狐新闻数据(SogouCS):https://www.sogou.com/labs/resource/cs.php
腾讯机器学习数据集:https://github.com/Tencent/tencent-ml-images
cifa数据集:
AVA数据集:
Model Zoo-机器学习预训练模型下载地址
网页地址:http://modelzoo.org/
MobileNet [Caffe][Caffe2]
Caffe MobileNet
Caffe2 MobileNet
SqueezeNet [CoreML]
V1.1
Caffe SqueezeNet
CoreML SqueezeNet
NCNN SqueezeNet
V1.0
Caffe SqueezeNet
VGG16 [CoreML]
CoreML VGG16
ResNet50 [CoreML]
CoreML ResNet50
Place205_GoogLeNet [CoreML]
CoreML Place205_GoogLeNet
InceptionV3 [CoreML]
CoreML InceptionV3
AlexNet [Caffe]
Caffe AlexNet
DensePose-实时人体姿态估计
DensePose 是Facebook 研究院开发的一种实时人体姿态估计方法,它能够将2D RGB 图像中的目标像素映射到3D 表面模型。DensePose 项目旨在通过这种基于3D 表面模型来理解图像中的人体姿态,并能够有效地计算2D RGB 图像和人体3D 表面模型之间的密集对应关系。与人体姿势估计需要使用10或20个人体关节(手腕,肘部等) 不同的是,DenPose 使用超过5000个节点来定义,由此产生的估计准确性和系统速度将加速AR和VR 工作的连接。
相关链接:
https://research.fb.com/facebook-open-sources-densepose/
Github 链接:
https://github.com/facebookresearch/DensePose
AlphaPose-姿态识别
由上海交通大学卢策吾团队发布的开源系统AlphaPose近日上线,该开源系统在标准测试集COCO上较现有最好姿态估计开源系统Mask-RCNN相对提高8.2%。Mask-RCNN是2017年以来计算机视觉领域的一个突破,获得了ICCV 2017最佳论文(马尔奖),涵盖了物体检测,分割,姿态估计。
AlphaPose 是基于腾讯优图和卢策吾团队在 ICCV 2017 上的分区域多人姿态识别算法(RMPE),该算法主要为了解决在人物检测结果不准的情况下进行稳定的多人姿态识别问题


—-
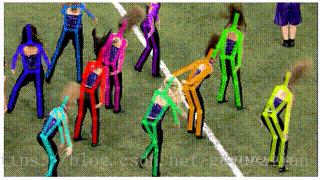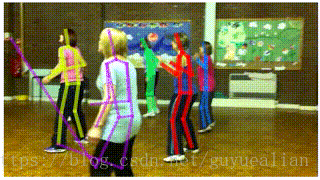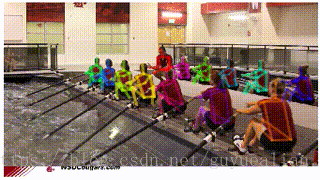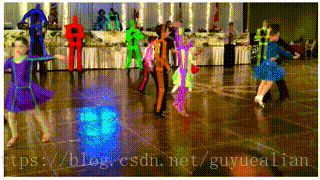
—-

相关链接:
http://mvig.sjtu.edu.cn/research/alphapose.html
Github 链接:
https://github.com/MVIG-SJTU/AlphaPose
MobilePose-支持移动设备、单人姿态估计框架
MobilePose 是一个轻量级的、基于 PyTorch 实现的支持移动设备、单人姿态估计框架。目标旨在提供一个模型训练/推理/评估接口,以及具有各种数据增强选项的数据采集器。最终训练的模型在速度、大小和精度方面均可满足移动设备的基本需求。
项目链接:
https://github.com/YuliangXiu/MobilePose-pytorch
NeuralEnhance: 提高图像分辨率的深度学习模型
NeuralEnhance是使用深度学习训练的提高图像分辨率的模型

项目地址:
https://github.com/alexjc/neural-enhance
FaceNet-人脸识别算法
谷歌人脸检测算法,发表于 CVPR 2015,利用相同人脸在不同角度等姿态的照片下有高内聚性,不同人脸有低耦合性,提出使用 cnn + triplet mining 方法,在 LFW 数据集上准确度达到 99.63%,在 youtube 人脸数据集上准确度 95.12%,比以往准确度提升了将近 30%。
论文地址:
FaceNet: A Unified Embedding for Face Recognition and Clustering
项目链接:
https://github.com/davidsandberg/facenet
Age and Gender Estimation-年龄和性别评估模型
该项目是一个基于 Keras 框架实现的 CNN 模型,用于根据人脸照片测算年龄和性别。
Github 链接:
https://github.com/yu4u/age-gender-estimation
CornerNet-Lite目标检测
《吊打YOLOv3!普林斯顿大学提出CornerNet-Lite,已开源》:https://mp.weixin.qq.com/s?__biz=MzI3MTA0MTk1MA==&mid=2652043490&idx=3&sn=42e64c635e12b20bc6f3818e2cb08efd&chksm=f1218c13c6560505bda9fdec38456d496a433a59ea3565d2770d202e770aa34cffed5f959cad&mpshare=1&scene=1&srcid=&key=12cf210ad33822ced47db9659a9ad9fb06d9b43514839b0e51d2c7cc295e6aa5a513958cb839e083d936417df7e2529e28499c2768bf78c6dc659bb01444656b0a8e1e9876e18c047345dfcac20e4c5f&ascene=1&uin=MTcyMzIzMzM4Mg%3D%3D&devicetype=Windows+10&version=62060739&lang=zh_CN&pass_ticket=EW7xEsUmTqF2PN1BvGoSkdfU8Px1FTqAASG0hmuXkMmXyT2kLwfRnQtRm8MknQLj
OD Annotation-目标检测数据集标注工具
本项目是一个目标检测数据集标注工具,采用 Python-flask 框架开发,基于 B/S 方式交互,支持多人同时标注。
项目特点如下:
B/S 方式交互
支持多人同时标注(可分配不同标注人员的标注范围,或不同人员标注不同类别)
类别采用选择方式,免去手工输入类别工作
支持拖拽方式修正标注区域
支持键盘方向键切换标注样本
Github 链接:
https://github.com/hzylmf/od-annotation
Semantic Segmentation PyTorch-语义分割工具包
本项目是由 MIT CSAIL 实验室开源的 PyTorch 语义分割工具包,其中包含多种网络的实现和预训练模型。自带多卡同步 bn,能复现在 MIT ADE20K 上 SOTA 的结果。ADE20K 是由 MIT 计算机视觉团队开源的规模最大的语义分割和场景解析数据集。

项目链接
https://github.com/CSAILVision/semantic-segmentation-pytorch
Photo Aesthetics Ranking Network -图像美学排名网络
使用caffe实现的图像美学质量评价模型
项目地址:
https://github.com/aimerykong/deepImageAestheticsAnalysis
Non-local Neural Networks for Video Classification-视频分类开源代码和模型
本项目是 Facebook 论文 Non-local Neural Networks 的视频分类开源代码和模型,这个代码在视频分类效果和效率上都做到了很大的提升,ResNet-50 Non-local Net 基本能横扫只用 RGB 的视频分类模型。代码里面提供的模型可以作为许多其他任务的底层 representation,作者希望通过这个代码能把大规模视频相关的研究带进寻常百姓家。
项目链接:
https://github.com/facebookresearch/video-nonlocal-net
colornet-将灰度图转为彩色图
一个使用神经网络模型将灰度图转为RGB彩色图
项目链接
https://github.com/pavelgonchar/colornet
Visual Search Server-可视化搜索服务器
一个简单使用TensorFlow,InceptionV3模型和AWS GPU实例实现的视觉搜索服务器。代码实现两个方法,一个处理图像搜索的服务器和一个提取pool3功能的简单索引器。 最近邻搜索可以使用近似(更快)或使用精确方法(更慢)以近似方式执行。
项目地址:
https://github.com/AKSHAYUBHAT/VisualSearchServer
Darts-可微分的卷积循环网络结构
Darts 是 CMU 联合DeepMind 团队研发的一种可微分的卷积循环网络结构,它能够基于结构表征的连续性,通过梯度下降法来更有效地进行结构搜索。在CIFAR-10,ImageNet,Penn Treebank 和WikiText-2 等大型数据库的实验验证了这种结构在卷积图像分类和循环语言建模方面的高效性能。
论文链接:
https://arxiv.org/pdf/1806.09055.pdf
Github 链接:
https://github.com/quark0/darts
SNIPER-高效的多尺度训练方法
SNIPER 是一种高效的多尺度训练方法,可用于诸如目标检测,实例分割等图像识别任务。与图像金字塔处理图像中每个像素不同,SNIPER 是选择性地处理真实目标周围区域的像素。得益于其能在低分辨率的芯片上运行,这能够显着加速了多尺度训练进程。此外,高效的内存设计使得 SNIPER 在训练期间能够最大程度地受益于批量正则化方法 (BN),还能在单个 GPU 上实现更大批量的图像识别任务。因此,SNIPER 不需要跨 GPU 同步批量地处理统计数据,你可以像处理图像分类一样地训练你的目标检测器,简单而高效!
论文链接:
https://arxiv.org/pdf/1805.09300.pdf
Github 链接:
https://github.com/mahyarnajibi/SNIPER
Mace-用于移动端的、异构计算平台的深度学习推理框架
Mace 是一个用于移动端的、异构计算平台的深度学习推理框架。在运行期间,它通过结合NEON,OpenCL 和Hexagon 进行优化,并引入Winograd 算法来加速卷积计算,因此初始化过程也将更快地优化。此外,它能很好地支持图级内存分配优化和缓冲器重用过程,试图保持最小的外部依赖性以减少内存占用空间。它还能良好地覆盖高通(Qualcomm),联发科技(Media Tek),Pinecone 和其他基于ARM 的芯片,以CPU 运行时还能与大多数的POSIX 系统和性能有限的体系结构兼容。
Github 链接:
https://github.com/XiaoMi/mace
Robosat-端到端的特征提取方法
Robosat 是一种端到端的特征提取方法,能够用于航空和卫星图像的目标特征提取,包括图像中的建筑物,停车场,道路,汽车等目标。该方法主要包括三部分内容:
数据准备:为训练特征提取模型创建一个数据集。
训练和建模:为图像特征提取训练一个分割模型。
后处理:将图像分割结果转为干净而简单的几何形状。
Github 链接:
https://github.com/mapbox/robosat
DecaNLP-自然语言界的“十项全能”挑战
DecaNLP 是由Saleforce 提出的一个自然语言界的“十项全能”挑战,其涵盖了十项自然语言任务:问答,机器翻译,摘要,自然语言推理,情感分析,语义角色标记,零目标关系提取,目标导向对话,语义分析和常识代词解析等任务。每种任务都被视为是一种问答问题,可以通过我们提出的多任务问答模型框架(Multitask Question Answering Network) 来解决。该模型能够联合学习DecaNLP 挑战中的所有任务,而不需要在多任务设置下设定某个特定任务的模块或超参数。
论文链接:
https://arxiv.org/abs/1806.08730
Github 链接:
https://github.com/salesforce/decaNLP
Magnitude-快速高效的通用向量嵌入式实用程序包
Magnitude 是一种快速高效的通用向量嵌入式实用程序包,含有功能丰富的Python 包和矢量存储文件格式,可用于在Plasticity 中以快速、高效而简单的方式将矢量嵌入用于机器学习模型。它主要是为Gensim 提供一种更简单快速的替代方案,但也可以作为一种通用的矢量存储方法应用于NLP 以外的领域。
Github 链接:
https://github.com/plasticityai/magnitude
Porcupine-自助式的、高精度、轻量级文字检测引擎
Porcupine 是一种自助式的、高精度、轻量级文字检测引擎,它能够使开发人员构建语音应用程序平台。它具有以下几大优势:
自助式服务:你可以在几秒内选择任何的唤醒词(wake word) 并构建模型。
能够使用真实情况下训练的深度神经网络(即噪声和混响)。
结构紧凑且计算效率高,能够适用于物联网应用。
跨平台应用:以纯定点ANSIC 实现,目前可支持Raspberry Pi,Android,iOS,watchOS,Linux,Mac 和Windows 等平台。
可扩展性强:它可以同时检测数十个唤醒词(wake word),而几乎不需要额外的CPU /内存占用。
Github 链接:
https://github.com/Picovoice/Porcupine
NCRF-神经条件随机场结构,能够将检测到的癌症转移到WSI 中
NCRF是百度研究的一种神经条件随机场结构,能够将检测到的癌症转移到WSI 中。这种框架通过完全连接的条件随机场(CRF),将相邻补丁之间的空间相关性直接并入CNN 结构的顶层特征提取器,并采用标准的端到端训练方式,以反向传播法进行优化。实验结果表明这种框架能够获得更佳质量的预测概率图,并取得不错的平均FROC 分数。
论文链接:
https://openreview.net/pdf?id=S1aY66iiM
Github 链接:
https://github.com/baidu-research/NCRF
DALI-数据加载库
DALI 是NVIDA 提出的一个数据加载库,它是一个高度优化的构建模块和执行引擎集合,可用于加速深度学习应用程序中输入数据的预处理过程。此外,DALI 还提供了不同数据的加速提供了足够的性能和灵活性,并可以轻松集成到不同的深度学习训练和推理程序中。它具有以下几大优势:
能够直接从磁盘加速读取全数据,并为训练和推理过程做准备。
通过可配置的图形和自定义操作实现足够的灵活性。
支持图像分类和分段工作负载。
直接通过框架插件和开源绑定轻松实现集成。
具有多种输入格式的便携式训练工作流程,包括JPEG,LMDB,RecordIO,TFRecord 等格式。
Github 链接:
https://github.com/NVIDIA/dali
如果你觉得该帖子帮到你,还望贵人多多支持,鄙人会再接再厉,继续努力的~
————————————————
版权声明:本文为CSDN博主「pan_jinquan」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/guyuealian/article/details/81223084
チン ガ administrator
コメントを残す
コメントを残す

LPursuing truth, goodness and beauty, our mission is to promote people's health and world peace.
著者について